Teaching LLMs to Reason About Finance: A Deep Dive into FinQA
Can we teach AI to understand financial reports the way expert analysts do? This question drove my research project in Carnegie Mellon's Large Language Models course, where I explored how modern LLMs can generate not just answers, but transparent reasoning programs for complex financial questions.
The Challenge: Beyond Simple Question-Answering
Financial analysis presents a unique challenge for AI systems. Unlike simple factual questions, analyzing earnings reports requires models to extract precise values from dense tables, chain multiple mathematical operations together, explain their reasoning for regulatory compliance, and compute accurate numerical results without hallucination.
Traditional language models often struggle with arithmetic, producing plausible but incorrect calculations. The FinQA dataset addresses this by requiring models to generate executable symbolic programs that demonstrate their logical reasoning steps while producing verifiable numerical answers.
Understanding the FinQA Task
The FinQA dataset contains expert-annotated question-answer pairs from S&P 500 company earnings reports. Each example includes a natural language question, hybrid context combining unstructured text and structured financial tables, a gold symbolic reasoning program showing the correct sequence of operations, and the expected numerical answer.
Dataset Statistics:
- Training: 6,251 examples
- Development: 883 examples
- Test: 1,147 examples
- Supported operations: add, subtract, multiply, divide, greater, exp
For example, given the question "What is the percentage change in net revenue from 2014 to 2015?" with appropriate table data, the model should generate:
subtract(5829, 5735)
divide(#0, 5735)
multiply(#1, 100)
This program transparently shows each reasoning step: subtracting the earlier year from the later year, dividing by the base year to get the rate of change, and multiplying by 100 to convert to percentage format.
Experimental Approach: Three Complementary Methods
I investigated three approaches to solving this task, each revealing different insights about how LLMs handle financial reasoning.
1. In-Context Learning: Testing Zero-Shot and Few-Shot Capabilities
In-context learning (ICL) evaluates how well pre-trained models can solve tasks purely from demonstrations in the prompt, without any parameter updates. I tested both Mistral-7B-Instruct-v0.2 and Meta-Llama-3-8B-Instruct across zero-shot, three-shot, and five-shot configurations.
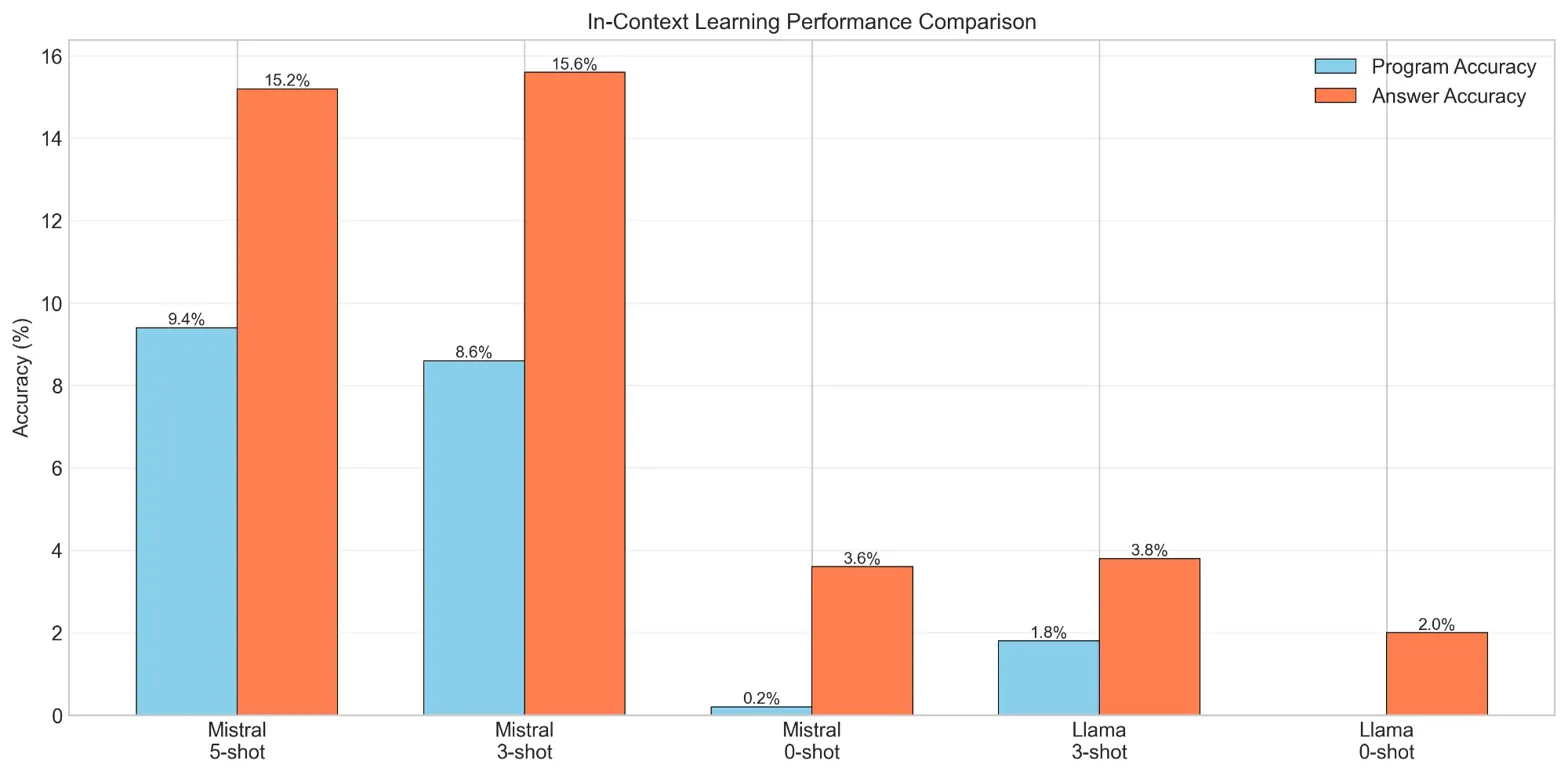
Key Finding: Prompt style dramatically impacts performance. Instruction-based prompts with formal, technical language and explicit operation definitions consistently outperformed conversational prompts. For Mistral-7B at five-shot, instruction-based prompts achieved 15.2% answer accuracy versus just 7.2% for conversational style—a 2.1× improvement.
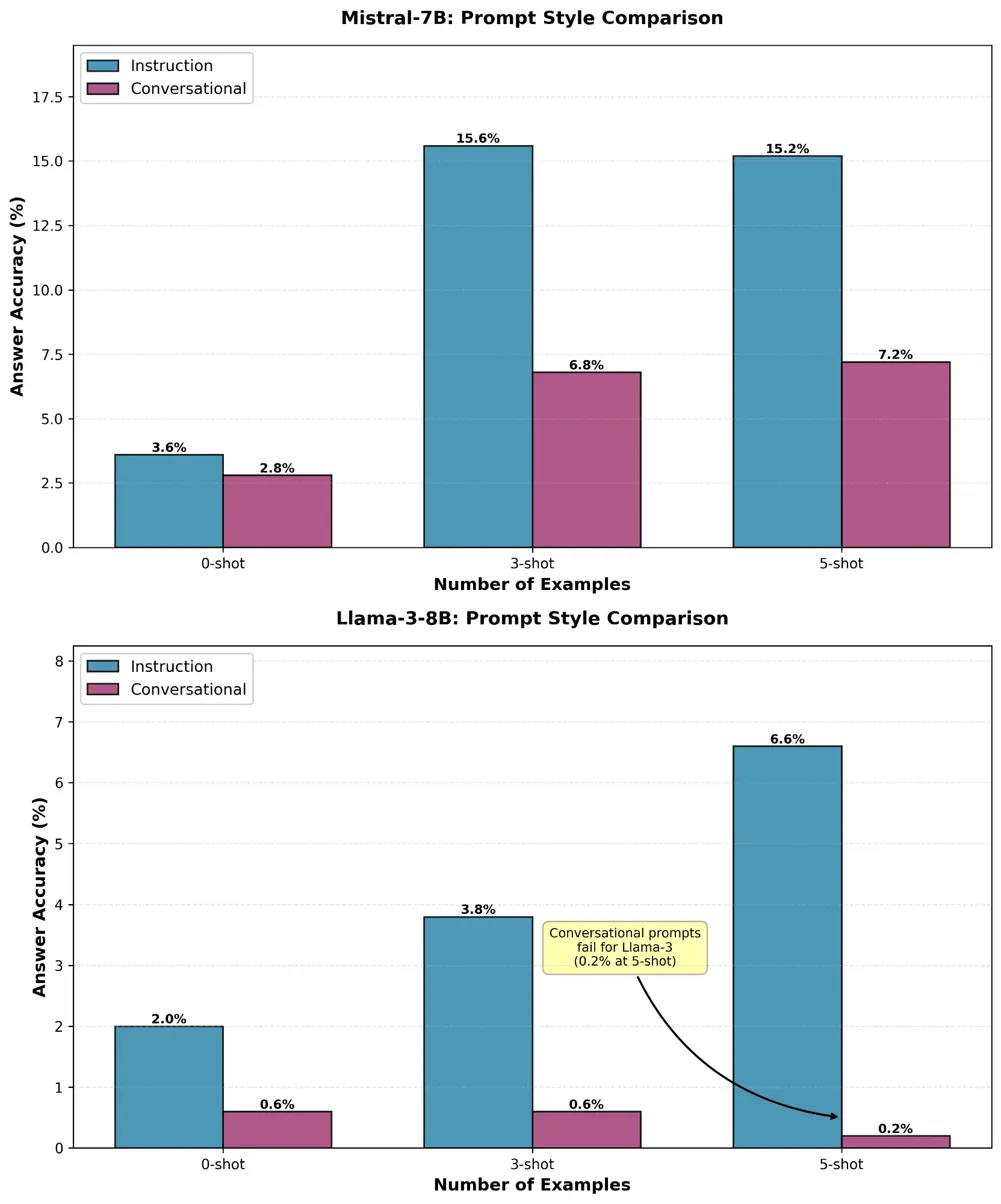
The results revealed that few-shot prompting significantly beats zero-shot (Mistral-7B improved from 3.6% to 15.6% with just three examples), but performance saturates quickly beyond 3–5 demonstrations. This suggests fundamental limitations in what ICL alone can achieve for complex reasoning tasks.
2. LoRA Fine-Tuning: Parameter-Efficient Specialization
Low-Rank Adaptation (LoRA) enables efficient fine-tuning by training small adapter layers while keeping the base model frozen. I trained adapters with just 8.39 million parameters—representing only 0.1% of the total model weights—for approximately $3–4 per model on AWS infrastructure.
Training Configuration:
- Rank (r): 8, Alpha: 16
- Target modules: q_proj, v_proj, k_proj, o_proj
- Learning rate: 2e-4 with linear warmup
- 3 epochs on 6,251 training examples
- Hardware: AWS g5.2xlarge (NVIDIA A10G 24GB)
- Training time: 2.5-3 hours per model
- Final adapter size: ~50MB
Dramatic Performance Gains: LoRA fine-tuning substantially outperformed ICL for both models. Meta-Llama-3-8B improved from 3.8% (ICL) to 34.35% (LoRA), representing a 9× improvement in answer accuracy. Mistral-7B improved from 15.2% to 24.85%, a 1.6× gain.
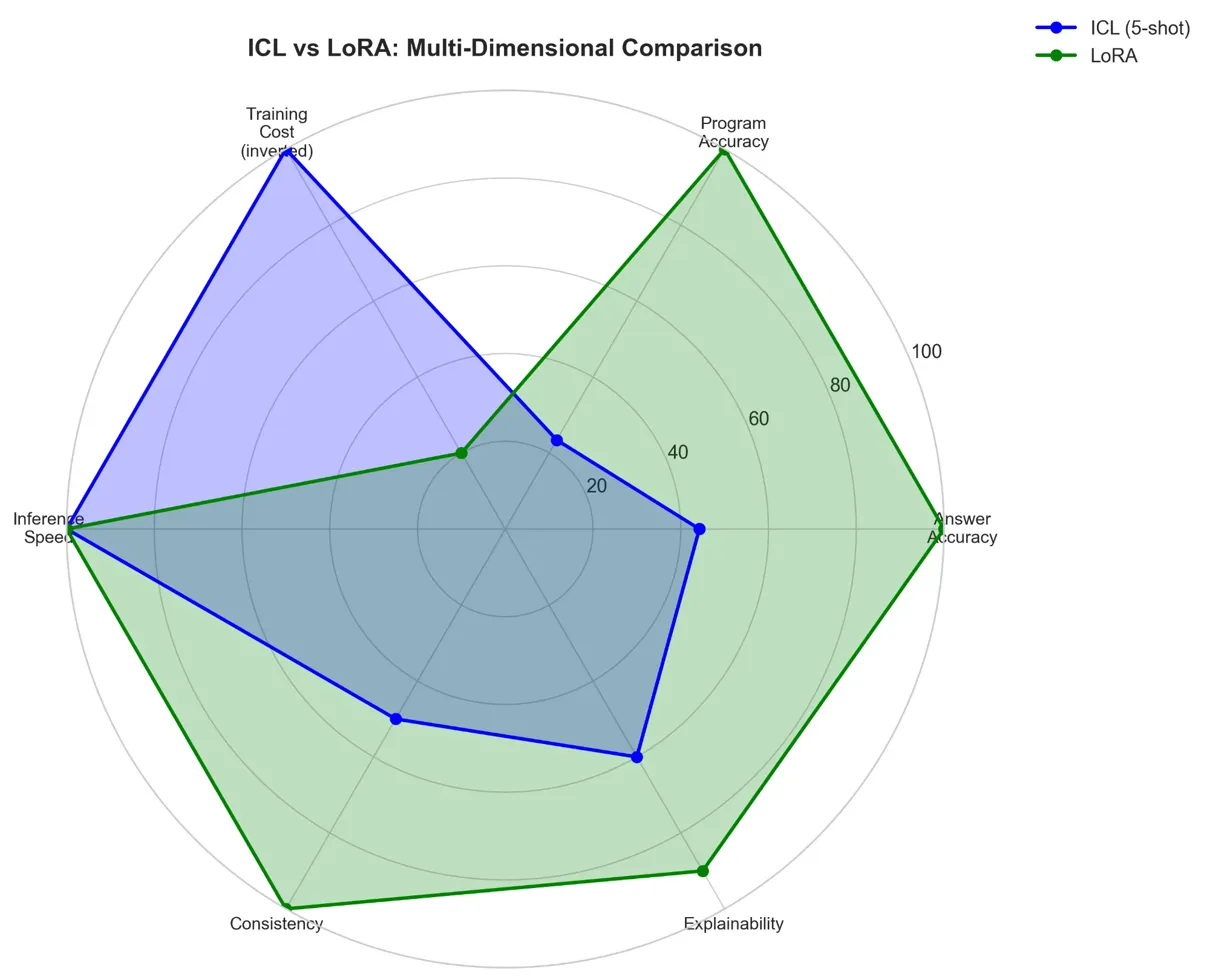
Interestingly, model rankings reversed between ICL and fine-tuning. While Mistral-7B outperformed Llama-3-8B in ICL scenarios (15.2% versus 3.8%), after fine-tuning, Llama-3-8B surpassed Mistral-7B (34.35% versus 24.85%). This suggests that ICL performance doesn't reliably predict fine-tuning potential, and that larger models benefit more from task-specific adaptation.
3. Tool-Calling: Neuro-Symbolic Integration for Arithmetic Reliability
Even when models generate perfectly correct reasoning programs, do they compute accurate numerical answers? This question motivated my tool-calling experiment, which integrated external symbolic execution to handle arithmetic operations.
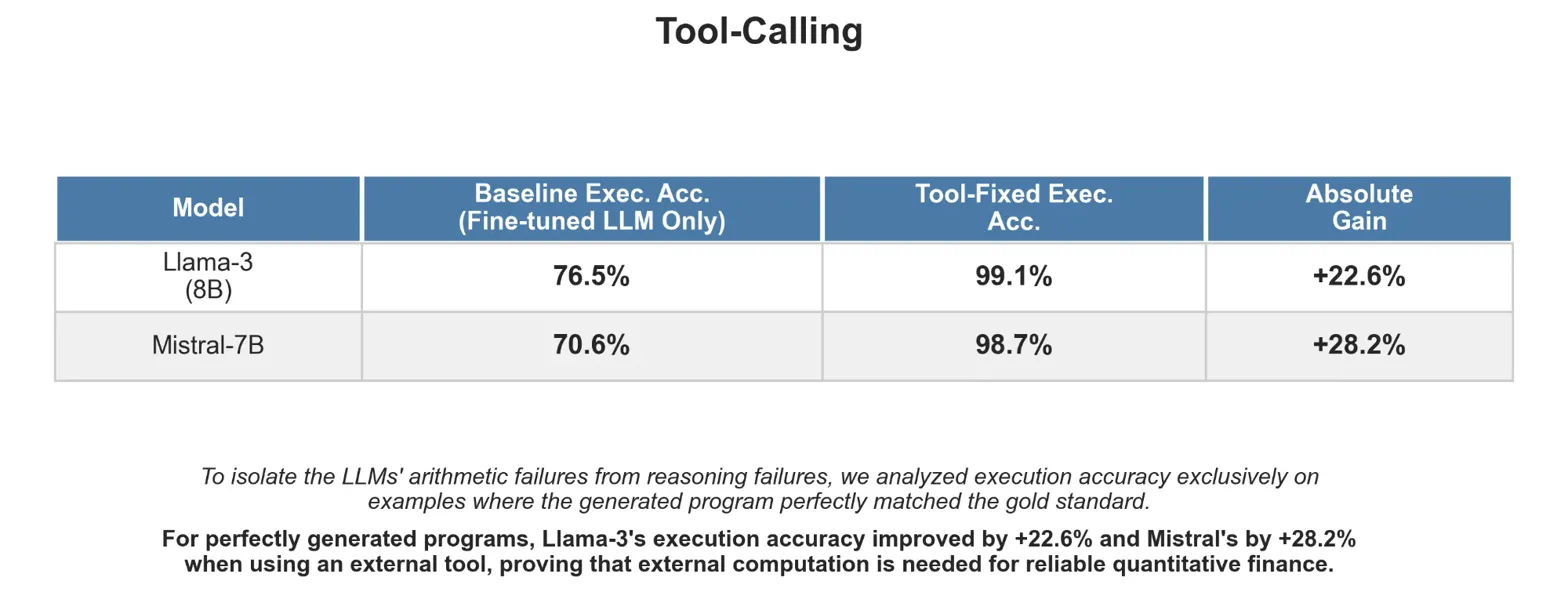
Critical Discovery: For examples where the generated program perfectly matched the gold standard, using the LLM's own arithmetic yielded only 70–76% execution accuracy. Delegating computation to an external symbolic executor boosted this to 98–99%—a +22.6% improvement for Llama-3 and +28.2% for Mistral-7B.
This proves that even when reasoning logic is correct, LLMs struggle with precise arithmetic. Reliable quantitative finance requires a neuro-symbolic architecture where LLMs handle program generation while symbolic tools ensure computational precision.
Deployment Recommendations: LoRA for Production
Based on comprehensive evaluation across accuracy, cost, and operational metrics, I recommend deploying LoRA fine-tuned Meta-Llama-3-8B-Instruct for production use. This configuration achieves the highest answer accuracy (34.35%) and program accuracy (40.10%) while training only 0.1% of parameters.
Why LoRA Over ICL?
The one-time training investment of $3–4 yields more than double the accuracy of ICL, provides consistent outputs without sensitivity to prompt variations, eliminates per-query demonstration processing overhead, and generates more reliable reasoning chains with 40% program accuracy versus 9% for ICL.
When to Use Each Approach:
In-context learning remains valuable for rapid prototyping, situations with very limited training data (fewer than 100 examples), deployment across multiple diverse tasks without task-specific training, and scenarios where training infrastructure is unavailable.
LoRA fine-tuning is preferred when sufficient training data exists (1000+ examples), task-specific performance is critical for production, long-term deployment requires consistent performance, and explainability matters for regulatory compliance.
Real-World Impact and Future Directions
This research demonstrates that small LoRA adapters effectively specialize open LLMs for financial reasoning at minimal cost. The 50MB adapter can be easily versioned, updated, and swapped, providing significant operational advantages over full model training.
However, important limitations remain. Answer accuracy of 34% requires human verification for production use. The concentration of errors in value extraction (60% of failures) represents the primary target for future improvements. Training exclusively on S&P 500 data means generalization to other domains requires validation.
Future Research Directions:
Improved table understanding through vision-language models or specialized table encoders could address the dominant failure mode. Multi-modal approaches combining text and visual table representations may enhance value extraction. Ensemble methods combining multiple reasoning paths could improve robustness. Extended training on diverse financial documents beyond S&P 500 reports would enhance generalization.
Key Takeaways
This project revealed several critical insights about LLMs for financial reasoning:
-
Parameter-efficient fine-tuning works remarkably well. Training only 0.1% of model weights achieves 9× improvement over in-context learning at minimal cost.
-
External computation is essential for reliability. Even perfectly correct reasoning programs require symbolic execution to achieve 99% arithmetic accuracy.
-
Value extraction remains the bottleneck. Future improvements will primarily come from better table understanding, which currently accounts for 60% of remaining errors.
-
Model selection depends on use case. ICL performance doesn't predict fine-tuning potential—Llama-3-8B surpassed Mistral-7B after adaptation despite weaker zero-shot capabilities.
The combination of efficient fine-tuning and neuro-symbolic integration points toward a practical path for deploying LLMs in quantitative finance, where both reasoning transparency and computational reliability are essential.
Project Resources
The complete implementation, including training scripts, evaluation code, and configuration files, is available on GitHub:
Repository: github.com/abhisvakil/FinQA-Mini-Project
Quick Start
To reproduce these experiments:
# Clone the repository
git clone https://github.com/abhisvakil/FinQA-Mini-Project.git
cd FinQA-Mini-Project
# Setup environment
conda env create -f environment.yml
conda activate finqa-mini
# Prepare data
cd src && python data_loader_simplified.py && cd ..
# Run LoRA training (2.5-3 hours per model)
./run_all_experiments.sh train-lora-llama
./run_all_experiments.sh train-lora-mistral
# Evaluate
python src/evaluate.py --predictions_file results/predictions/Meta-Llama-3-8B-Instruct_lora_predictions.json
The repository includes YAML-driven configuration for reproducible experiments, unified inference pipelines for both LoRA and ICL methods, organized results structure for easy comparison, and complete evaluation scripts with detailed metrics.
Academic References
This work builds upon several foundational papers in financial reasoning and parameter-efficient fine-tuning:
FinQA Dataset:
@inproceedings{chen2021finqa,
title={FinQA: A Dataset of Numerical Reasoning over Financial Data},
author={Chen, Zhiyu and Chen, Wenhu and Smiley, Charese and Shah, Sameena and
Borova, Iana and Langdon, Dylan and Moussa, Reema and Beane, Matt and
Huang, Ting-Hao and Routledge, Bryan and Wang, William Yang},
booktitle={Proceedings of EMNLP},
year={2021}
}
LoRA: Low-Rank Adaptation:
@article{hu2021lora,
title={LoRA: Low-Rank Adaptation of Large Language Models},
author={Hu, Edward J and Shen, Yelong and Wallis, Phillip and
Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and
Wang, Lu and Chen, Weizhu},
journal={arXiv preprint arXiv:2106.09685},
year={2021}
}
Additional Resources:
- FinQA Paper: arxiv.org/abs/2109.00122
- LoRA Paper: arxiv.org/abs/2106.09685
- Meta-Llama-3-8B-Instruct: huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
- Mistral-7B-Instruct-v0.2: huggingface.co/mistralai/Mistral-7B-Instruct-v0.2
This research was completed as part of the Large Language Models course (11-667) at Carnegie Mellon University in Fall 2024. The project was a collaborative effort with Abhi Vakil and Akshita Verma. Full implementation details and reproducibility information are available in the GitHub repository.
Suggested Posts
Giving Embodied Agents Memory: How Graph Databases Enable Smarter Long-Horizon Planning
Exploring how integrating graph-based episodic memory into embodied agents improves long-horizon task completion, reduces action repetition, and enables learning from past mistakes in complex household environments.
Teaching Robots to See and Act: Building a Vision-Language Model for Precise Manipulation
Exploring how combining 3D perception, depth estimation, and visual in-context learning enables embodied agents to achieve 71.67% accuracy on complex manipulation tasks, outperforming state-of-the-art multimodal language models.
Building the Future of Autonomous Trading: From User Intent to Agent Execution
Exploring how the Agentic Trading Platform transforms cryptocurrency trading through intelligent agents that operate autonomously with user-defined strategies and risk parameters.