Teaching Robots to See and Act: Building a Vision-Language Model for Precise Manipulation
How do you teach a robot to understand "stack the purple cube on the metal container"? This seemingly simple instruction requires perceiving 3D space, understanding language semantics, and executing precise 7-degree-of-freedom movements. In my Multimodal Machine Learning course at Carnegie Mellon, our team tackled this challenge by building a novel architecture that bridges the gap between high-level language instructions and low-level robotic control.
The Challenge: From Words to Actions
Imagine trying to control a robotic arm using only natural language. You can say "pick up the red mug," but how does the robot translate those words into exact motor commands? It needs to locate the mug in 3D space, plan a collision-free path, orient its gripper correctly, and execute precise movements—all while understanding that "red mug" refers to a specific object among many distractors.
This is the symbol grounding problem: connecting abstract language to concrete physical actions. Traditional approaches often fail because they either excel at language understanding but lack spatial reasoning, or they're great at vision but miss the semantic intent.
Our Solution: Visual In-Context Learning with 3D Perception
We developed a modular architecture that explicitly addresses spatial reasoning before performing language-conditioned control. The key insight: rich 3D representations matter more than simply throwing vision and language at a transformer.
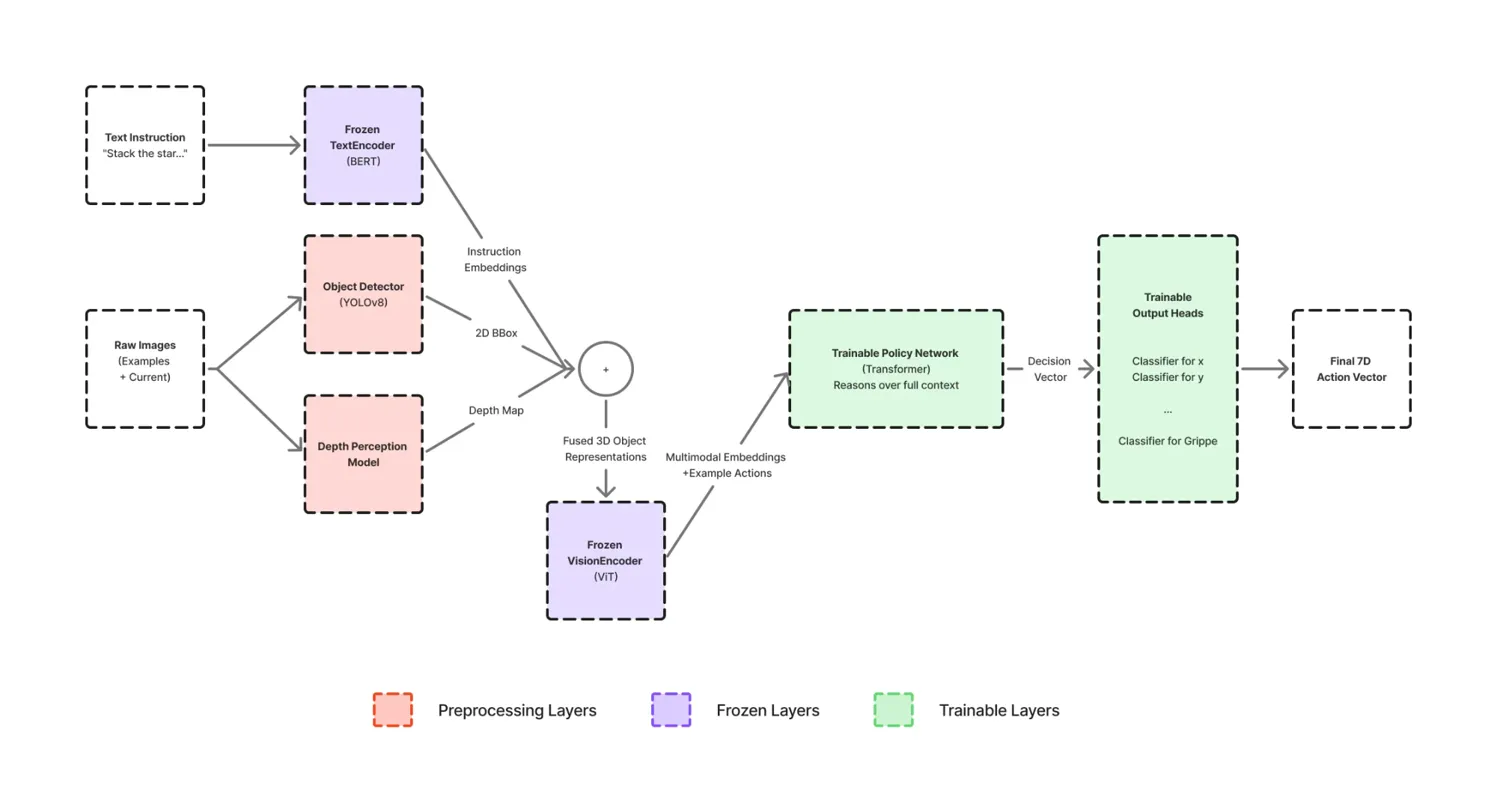
Our pipeline consists of five carefully designed stages that work in harmony:
Stage 1: 3D Perception Preprocessing
Rather than feeding raw RGB images directly into a neural network, we first create explicit 3D object representations. For each input frame, we:
- Detect objects using YOLOv8, identifying what's in the scene and providing 2D bounding boxes
- Estimate depth using MiDaS to understand how far each object is from the camera
- Fuse 2D and 3D information by combining bounding boxes with depth statistics to create object-centric descriptors that answer both "what" and "where in 3D space"
This preprocessing transforms cluttered visual scenes into structured, grounded representations that downstream components can reason about effectively.
Stage 2: Frozen Encoders (The "Eyes")
We leverage powerful pretrained models without modification:
- Text Encoder: BERT-base-uncased produces 768-dimensional instruction embeddings, capturing semantic meaning and task intent
- Vision Encoder: CLIP ViT-B/32 generates 512-dimensional features for each 3D object representation, bridging visual appearance with semantic concepts
By keeping these encoders frozen, we preserve their strong pretrained capabilities while focusing our training budget on the reasoning and control components.
Stage 3: Transformer Policy Network (The "Brain")
This is where the magic happens. We treat the entire task as a sequence modeling problem, feeding the Transformer:
- Instruction embeddings
- 3D object embeddings from demonstration frames
- Corresponding demonstration actions
- 3D object embeddings from the current scene
The self-attention mechanism learns to map instructions and visual context to appropriate actions by attending over demonstration trajectories. This enables visual in-context learning: the model learns from within-episode demonstrations during inference, adapting its behavior based on examples.
Stage 4: Factorized Action Heads (The "Hands")
Rather than predicting all action dimensions jointly, we use seven separate classification heads, one for each degree of freedom:
- Translation: x, y, z (101 bins each)
- Rotation: roll, pitch, yaw (121 bins each)
- Gripper: open/close (2 bins)
This factorization encourages the policy to learn disentangled control while sharing information through the Transformer backbone. It also enables detailed per-dimension analysis and calibration.
Training: Parameter-Efficient Learning at Scale
We curated a dataset of 1,772 examples from EmbodiedBench's manipulation tasks, split 80/10/10 into train/validation/test sets. Each example contains:
- Natural language instruction
- Two visual demonstration frames
- Current observation frame
- Ground-truth 7D action aligned with discrete bins
Training Configuration:
- Infrastructure: AWS EC2 g5.2xlarge (24GB GPU)
- Batch Size: 8 (memory-constrained due to multimodal pipeline)
- Learning Rate: 1×10⁻⁴ with Adam optimizer
- Epochs: 42 with early stopping (patience=5)
- Best Checkpoint: Epoch 36
The model converged beautifully, reducing training loss by 77.8% from initialization. We observed rapid initial improvement in the first 10-15 epochs as the Transformer learned basic instruction-action correspondences, followed by continued refinement through epoch 36.
Results: Surpassing State-of-the-Art Models
Our visual ICL model achieved 71.67% overall per-action accuracy on the held-out test set—dramatically outperforming both baseline approaches and state-of-the-art multimodal language models.
| Method | Success Rate (%) |
|---|---|
| Random Policy | ~1.0 |
| Language-Only (OpenLLaMA-7B) | 13.4 |
| Vision-Only (ResNet-50) | 22.6 |
| CLIPort | 0.0 |
| Gemini-1.5-Pro | 16.2 |
| InternVL3-78B | 26.3 |
| Claude-3.5-Sonnet | 28.5 |
| GPT-4o (SOTA) | 28.9 |
| Our Visual ICL Model | 71.7 |
The 2.5× improvement over GPT-4o demonstrates that specialized architectures with explicit 3D reasoning significantly outperform general-purpose models on tasks requiring precise spatial control.
Per-Action Performance: Understanding Strengths and Weaknesses
Breaking down accuracy by action dimension reveals fascinating patterns:
| Action Dimension | Accuracy | Category |
|---|---|---|
| Rotation X (Pitch) | 98.9% | Excellent |
| Rotation Y (Yaw) | 98.9% | Excellent |
| Gripper (Open/Close) | 91.5% | Excellent |
| Rotation Z (Roll) | 83.5% | Good |
| Translation Z (Depth) | 64.8% | Good |
| Translation X | 36.4% | Challenging |
| Translation Y | 27.8% | Challenging |
Key Observations:
-
Rotation Excellence: Near-perfect performance on pitch and yaw rotations suggests the model effectively learns semantic affordances like "turn" or "orient toward"
-
Gripper Reliability: 91.5% accuracy on binary open/close decisions indicates robust understanding of task phases
-
Depth Advantage: Translation Z performs significantly better (64.8%) than X/Y translations, likely due to our explicit depth estimation module providing strong signals for the Z-axis
-
Fine-Grained Challenge: The lower X/Y translation accuracies (27.8-36.4%) reflect the difficulty of precise spatial positioning across 101 discrete bins—a harder problem than the more semantically distinct rotational patterns
Beyond Accuracy: Intrinsic Metrics for Robustness
Success rate alone doesn't tell the full story. We also measured intrinsic metrics that capture behavioral quality:
| Method | Detection Success ↑ | Invalid Actions ↓ |
|---|---|---|
| Language-only | 13.4% | 42.1% |
| Vision-only @ 224×224 | 17.0% | 35.4% |
| Vision-only @ 500×500 + FPN | 22.6% | 24.8% |
| GPT-4o | 28.9% | 22.0% |
| Claude-3.5-Sonnet | 25.4% | 24.6% |
| Our Visual ICL | 31.2% | 20.5% |
Our model achieves both the highest detection rate and the lowest invalid action rate, indicating it not only performs better but also behaves more safely and reliably.
Qualitative Insights: When It Works and When It Struggles
Success Cases: When instructions uniquely identify target objects (e.g., by color and shape) and 3D representations are unambiguous, the model reliably produces correct rotations and gripper actions. Attention maps show strong focus on corresponding object tokens and similar objects in demonstrations.
Translation Failures: The most common failures involve over- or under-shooting objects in the image plane. In cluttered scenes with multiple similar objects, the model sometimes snaps to a neighboring object with similar appearance but different position.
Ambiguous Instructions: For under-specified instructions like "move the cube closer" without a clear reference, the model mirrors human ambiguity—often moving toward the largest or most centrally located candidate, showing higher entropy in translation heads.
Multi-Object Reasoning: When tasks require reasoning about object relationships (e.g., "stack the star on the silver container"), the model generally identifies both objects but may mis-estimate the relative offset needed for safe placement.
Why This Architecture Works
Three design choices prove critical to our success:
1. Explicit 3D Grounding: Rather than expecting transformers to infer 3D structure from 2D images, we provide explicit depth and object-centric representations upfront. This reduces the burden on the Transformer and improves spatial reasoning.
2. Factorized Action Heads: Separate heads for each action dimension enable focused learning and better calibration per axis. This also facilitates debugging and targeted improvements.
3. Visual In-Context Learning: Including demonstration trajectories allows the model to adapt its behavior based on task-specific examples, leveraging the few-shot learning capabilities of transformers without requiring task-specific fine-tuning.
Future Directions: Scaling Toward Robust Embodied Agents
While our results are promising, several limitations point toward future research directions:
Continuous Control: The 101/121-way classification for translations/rotations makes fine-grained motions difficult. Moving to continuous action parameterization (e.g., mixture density networks) or hybrid approaches (coarse bins + residual regression) could improve precision.
Data Scale: 1,416 training examples is modest for a 7D action space. Many bin combinations are rarely seen during training, particularly for long-tail translations. Scaling up with targeted data augmentation should improve coverage.
Temporal Context: We treat tasks as single-step prediction, ignoring full episode trajectories. Integrating richer history and external memory could enable error recovery and multi-step planning.
Calibration & Safety: Adding confidence-based gating and temperature-scaled probability estimates could reduce invalid or risky actions before deployment on physical robots.
Cross-Environment Generalization: Our architecture is specialized to EmbodiedBench's manipulation setup. Adapting to real-world scenarios requires handling variable camera angles, lighting conditions, and object distributions.
Key Takeaways
This project demonstrates several important lessons for building embodied AI systems:
-
3D perception matters: Explicit depth estimation and object-centric representations significantly outperform end-to-end visual encoding for spatial tasks
-
Architecture specialization beats scale: Our targeted 8M-parameter policy network outperforms 70B+ parameter general-purpose models on manipulation tasks
-
Factorized control enables interpretability: Per-dimension action heads reveal exactly where models succeed and struggle, guiding targeted improvements
-
Visual demonstrations are powerful: In-context learning from visual examples enables adaptation without task-specific fine-tuning
The path to general-purpose embodied agents requires bridging high-level reasoning with low-level control. Our visual in-context learning architecture represents one step toward that goal—proving that thoughtful architectural design can dramatically improve performance on spatially grounded tasks.
Project Resources
The complete implementation, including model code, training scripts, and evaluation details, is available on GitHub:
Repository: github.com/0xlel0uch/EmbodiedMinds
This repository contains code for both the Visual ICL and Graph-RAG projects, with reproducible experimental setups and detailed documentation.
This research was completed as part of the Multimodal Machine Learning course (11-777) at Carnegie Mellon University in Fall 2024, in collaboration with Abhi Vakil, Daniel Chang, and Michael Zheng. The complete technical implementation and experimental details are available in the GitHub repository.
Suggested Posts
Giving Embodied Agents Memory: How Graph Databases Enable Smarter Long-Horizon Planning
Exploring how integrating graph-based episodic memory into embodied agents improves long-horizon task completion, reduces action repetition, and enables learning from past mistakes in complex household environments.
Teaching LLMs to Reason About Finance: A Deep Dive into FinQA
Exploring how large language models can understand financial reports through symbolic reasoning, comparing in-context learning with LoRA fine-tuning, and integrating external tools for reliable quantitative analysis.
Building the Future of Autonomous Trading: From User Intent to Agent Execution
Exploring how the Agentic Trading Platform transforms cryptocurrency trading through intelligent agents that operate autonomously with user-defined strategies and risk parameters.