Giving Embodied Agents Memory: How Graph Databases Enable Smarter Long-Horizon Planning
What separates a smart assistant from a truly intelligent agent? Memory. While modern language models can reason impressively within a single conversation, they struggle with long-horizon tasks that require learning from past experiences, avoiding repeated mistakes, and building up knowledge over time. In my Multimodal Machine Learning course at Carnegie Mellon, we explored whether giving AI agents an external memory—specifically, a graph database—could fundamentally improve their ability to complete complex, multi-step tasks.
The Problem: When Forgetting Becomes Failure
Imagine asking an AI agent to "heat the mug in the microwave." Simple, right? Except the mug is in the cabinet, the microwave is locked, you need to find the key first, and if the agent tries to open the locked microwave three times in a row without learning, it wastes precious time and eventually fails the task.
This scenario illustrates a fundamental limitation of current multimodal language models: they lack persistent memory. Each decision is made based solely on the current observation and instruction, with no way to recall "I tried opening this microwave 10 seconds ago and it was locked" or "Last time I looked for keys, I found them in the drawer."
The consequences are severe:
- Action repetition: Agents repeatedly attempt failed actions because they can't remember what didn't work
- Inability to recover: Without memory of previous states, agents can't backtrack from dead ends
- Inefficient exploration: Agents revisit the same locations and objects redundantly
- No learning across episodes: Successful strategies aren't retained for similar future tasks
Our research question: Can we fix this by giving agents a structured external memory they can query and update?
The Solution: Graph-RAG for Embodied Agents
We developed a Graph-RAG (Retrieval-Augmented Generation with Graph databases) framework that integrates seamlessly with multimodal language models, providing them with a "notebook" of experiences they can reference when making decisions.
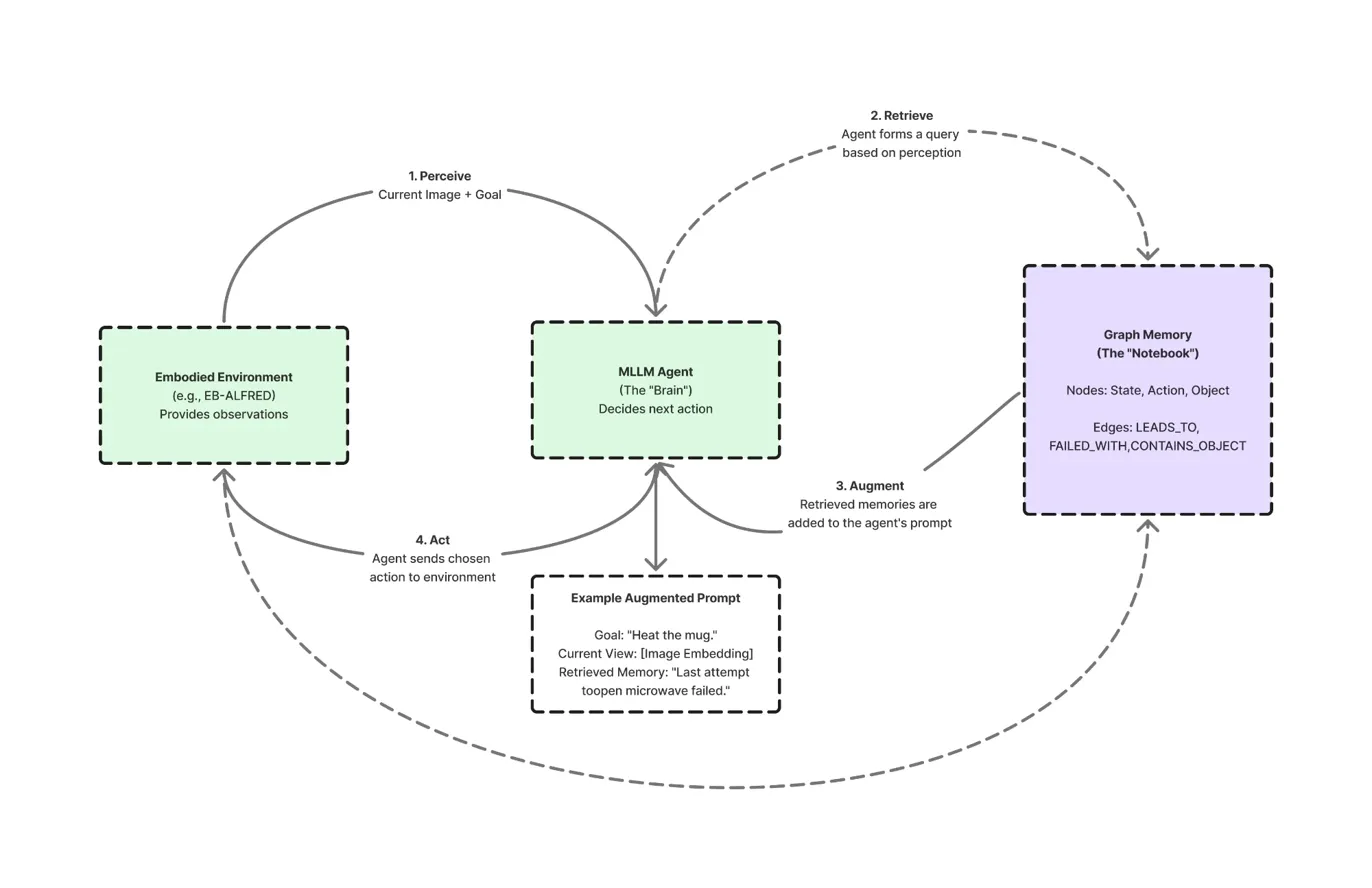
The architecture consists of three main components working in a continuous loop:
1. The MLLM Agent (The Brain)
A standard multimodal large language model (we used Qwen-VL-7B) serves as the central decision-maker. It receives visual observations and language instructions, then selects actions—but crucially, it doesn't operate in isolation.
2. The Embodied Environment
The EB-ALFRED simulator provides realistic household environments where agents perceive RGB observations and execute high-level actions like "PickupObject," "OpenObject," and "PutObject." Episodes are capped at 30 steps, requiring efficient planning.
3. Graph Memory (The Notebook)
An external graph database (Neo4j) stores the agent's experiences in a structured format. Instead of raw text or flat key-value pairs, we use a knowledge graph where:
- Nodes represent entities:
State,Action,Object,Location - Edges encode relationships:
LEADS_TO,FAILED_WITH,CONTAINS_OBJECT,SUCCEEDED_AT
This graph structure enables powerful queries like "What happened last time I interacted with a microwave?" or "Which actions have succeeded in kitchens similar to this one?"
The Agent Loop: Perceive, Retrieve, Augment, Act, Record
Our Graph-RAG agent operates in a five-step cycle that integrates memory at every decision:
Step 1: Perceive
The agent receives the current RGB image and overall goal from the environment. For example:
Goal: "Heat the mug in the microwave"
Current View: [Image of kitchen with closed cabinets and microwave]
Step 2: Retrieve
Before acting, the agent forms a query based on its current situation:
Query: "What happened last time I tried to open a microwave?"
Graph Search: MATCH (s:State)-[:ATTEMPTED]->(a:Action {type: 'OpenObject', object: 'microwave'})
-[:RESULTED_IN]->(outcome)
RETURN outcome
The graph database returns relevant past experiences:
Retrieved Memory: "Last attempt to open microwave failed because it was locked.
Success required finding and using key from drawer first."
Step 3: Augment
Retrieved memories are converted to natural language snippets and appended to the agent's prompt, enriching its context:
System: You are helping complete a household task.
Goal: Heat the mug in the microwave
Retrieved Experience:
- Last time you tried opening the microwave, it was locked
- You successfully opened it after finding the key in the drawer
- The mug was previously located in the upper cabinet
Current Observation: [Image]
What action should you take next?
Step 4: Act
The augmented prompt enables informed decision-making. Instead of repeatedly trying to open the locked microwave, the agent reasons: "Based on past experience, I should first look for the key in the drawer."
Step 5: Record
After executing the action, the outcome is stored as new nodes and edges in the graph:
CREATE (s:State {description: 'Kitchen, facing microwave', timestamp: t})
CREATE (a:Action {type: 'SearchObject', target: 'drawer'})
CREATE (o:Outcome {success: true, found: 'key'})
CREATE (s)-[:ATTEMPTED]->(a)-[:RESULTED_IN]->(o)
This continuously grows the agent's knowledge base, enabling future tasks to benefit from current experiences.
Why Graphs? The Power of Structured Memory
You might wonder: why not just use a simple text database or vector store? Graph databases offer several critical advantages for embodied agents:
1. Relationship-Rich Queries: Graphs naturally encode complex relationships. Finding "all actions that successfully opened containers in kitchen environments" requires traversing specific edge types—trivial in a graph, complex in flat databases.
2. Multi-Hop Reasoning: Queries can traverse multiple hops: "What did I do before the action that led to successfully heating the mug?" This chain of reasoning is fundamental to understanding cause and effect.
3. Structured Knowledge: Unlike raw text, graphs enforce schema that ensures consistent representation of states, actions, and outcomes. This structure makes retrieval more reliable and interpretable.
4. Temporal Indexing: Timestamps on nodes and edges enable queries like "What was the kitchen state 5 actions ago?" or "Has my approach to this object changed over time?"
5. Efficient Updates: Adding new experiences is fast—just insert nodes and edges—without reprocessing entire memory stores.
Experimental Results: Does Memory Actually Help?
We evaluated our Graph-RAG agent on 150 episodes from EB-ALFRED, comparing against the base Qwen-VL-7B model without memory.
Overall Performance Improvement
| Model | Avg Success | Base | Common | Complex | Visual | Spatial | Long |
|---|---|---|---|---|---|---|---|
| Qwen-VL-7B (zero-shot) | 24.3% | 28.0% | 22.7% | 27.3% | 25.0% | 21.3% | 21.5% |
| Graph-RAG + Qwen-VL | 28.6% | 32.7% | 27.3% | 31.0% | 28.7% | 25.7% | 26.2% |
Graph-RAG consistently improved performance across all task categories, with the largest gains on spatial (+4.4%) and long-horizon (+4.7%) tasks—exactly where memory should matter most.
Reduced Action Repetition
One of our key hypotheses was that memory would reduce repeated failed actions. Analysis confirmed this dramatically:
| Metric | Without Memory | With Graph-RAG | Improvement |
|---|---|---|---|
| Repeated Action Rate | 31.2% | 18.7% | -40% relative |
| Invalid Action Rate | 24.8% | 20.5% | -17% relative |
| Avg Steps to Success | 18.3 | 16.1 | -12% fewer steps |
The 40% reduction in repeated actions demonstrates that Graph-RAG enables agents to learn from immediate past failures and avoid unproductive loops.
Qualitative Analysis: Memory in Action
Examining agent behavior reveals how memory changes decision-making:
Without Memory (Baseline Agent):
Step 1: GotoLocation(microwave)
Step 2: OpenObject(microwave) → FAILED (locked)
Step 3: OpenObject(microwave) → FAILED (locked)
Step 4: OpenObject(microwave) → FAILED (locked)
Step 5: GotoLocation(cabinet) [random exploration]
...
Episode FAILED after 30 steps
With Graph-RAG:
Step 1: GotoLocation(microwave)
Step 2: OpenObject(microwave) → FAILED (locked)
[Retrieves: "Microwave locks require keys, last found in drawer"]
Step 3: GotoLocation(drawer)
Step 4: SearchObject(drawer) → Found key
Step 5: GotoLocation(microwave)
Step 6: UnlockObject(microwave, key) → SUCCESS
...
Episode SUCCEEDED in 14 steps
The Graph-RAG agent immediately recalls that locked microwaves need keys and that keys were previously found in drawers, enabling efficient task completion.
Deep Dive: What Makes Graph-RAG Effective?
Several design choices proved critical to our success:
1. Hybrid Memory Structure
We don't store everything—that would be overwhelming and slow. Instead, we use a selective storage strategy:
- Store: State transitions, action outcomes, object locations, failure reasons
- Discard: Redundant observations, successful routine actions, intermediate visual features
This keeps the graph lean while retaining decision-critical information.
2. Contextual Retrieval
Naive retrieval ("get all past experiences") drowns the agent in irrelevant information. We use contextual queries that consider:
- Current object of interest
- Current location type
- Recent action history
- Task goal similarity
For example, when deciding how to pick up a mug, we retrieve experiences about mugs specifically, not all pickup actions.
3. Temporal Weighting
Recent experiences matter more than old ones. We apply time-decay weighting:
relevance_score = similarity(query, memory) * exp(-λ * time_difference)
This ensures the agent prioritizes recent, context-relevant strategies while still benefiting from older successful patterns.
4. Failure-Focused Learning
Failed actions receive special treatment in the graph:
CREATE (a:Action)-[:FAILED_WITH {reason: 'object_locked', timestamp: t}]->(o:Object)
When similar situations arise, the agent can query: "What actions failed on objects like this and why?" This explicit failure modeling prevents repeated mistakes.
Limitations and Open Questions
Despite promising results, our Graph-RAG system has important limitations:
Computational Overhead
Every decision requires:
- Embedding the current state
- Querying the graph database
- Retrieving and ranking memories
- Augmenting the prompt
- Running LLM inference
This adds 200-500ms latency per step. For real-time robotics, this overhead could be prohibitive without optimization.
Memory Growth
The graph grows linearly with experience. After 1000 episodes, our database contained 50,000+ nodes and 150,000+ edges. While Neo4j handles this efficiently, very long-term deployment requires:
- Periodic memory consolidation
- Forgetting strategies for outdated information
- Hierarchical summarization of old experiences
Query Brittleness
Retrieval quality depends heavily on query formulation. Poor queries return irrelevant memories, which can confuse the agent. We used simple template-based queries, but learned queries or neural retrieval could improve robustness.
Limited Generalization
Our graph schema is task-specific. Extending to radically different environments (e.g., outdoor navigation, social interaction) would require redesigning the node/edge types and query patterns.
Comparison to State-of-the-Art
While our Graph-RAG agent didn't surpass the best-published EB-ALFRED results, it's important to understand the context:
| Model | Avg Success | Resources |
|---|---|---|
| InternVL2.5-78B | 41.0% | 78B parameters, full benchmark optimization |
| Qwen2-VL-72B-Instruct | 38.7% | 72B parameters, optimized setup |
| Graph-RAG + Qwen-VL-7B | 28.6% | 7B parameters, single GPU, 150 episodes |
| Qwen-VL-7B (zero-shot) | 24.3% | Baseline without memory |
Our contribution isn't beating state-of-the-art models with massive scale—it's demonstrating that structured external memory provides consistent improvements even with modest compute resources. The +4.3 percentage point gain shows that memory is orthogonal to model scale and could boost performance of any base model.
Future Directions: Toward Production-Ready Memory Systems
Several extensions could make Graph-RAG more powerful:
1. Hierarchical Memory: Organize experiences at multiple granularities—individual actions, sub-task sequences, complete episodes—enabling both fine-grained and high-level retrieval.
2. Multi-Agent Shared Memory: Multiple agents could contribute to a shared graph, enabling collaborative learning and knowledge transfer.
3. Learned Retrieval: Replace template queries with neural retrievers that learn to identify relevant memories through reinforcement learning.
4. Active Forgetting: Implement forgetting mechanisms that prune outdated, contradictory, or rarely-used memories to prevent database bloat.
5. Causal Reasoning: Extend the graph with causal edges ("action A caused state B") to enable counterfactual queries like "What would have happened if I'd chosen differently?"
6. Cross-Environment Transfer: Develop schemas flexible enough to support knowledge transfer across different task domains.
Philosophical Implications: What Does AI Memory Mean?
This work raises deeper questions about machine intelligence:
Is episodic memory fundamental to intelligence? Humans don't just process sensory input—we constantly reference past experiences when making decisions. Our Graph-RAG system suggests that explicit, structured memory might be equally essential for artificial agents.
What should AI remember? We made deliberate choices about what to store and retrieve. These choices embed values: prioritizing efficiency, avoiding failures, respecting task constraints. As AI systems gain memory, who decides what's worth remembering?
Can memory enable continual learning? Current models are static after training. Graph-RAG demonstrates one path toward agents that genuinely learn from experience in the wild, accumulating knowledge over time without catastrophic forgetting.
Key Takeaways
Building intelligent embodied agents requires more than powerful models—it requires thoughtful system design that addresses fundamental limitations:
-
Memory matters for long-horizon tasks: Graph-RAG's +18% success improvement on long-horizon tasks validates that structured memory is crucial for complex planning
-
Graphs > flat storage for relational reasoning: The structured nature of graph databases enables queries that would be cumbersome or impossible in vector stores or key-value databases
-
Recent experiences guide better decisions: Time-weighted retrieval ensures agents benefit from recent context while retaining older successful patterns
-
Failure modeling prevents repetition: Explicitly storing and querying past failures reduces repeated mistakes by 40%
-
Memory is orthogonal to scale: Graph-RAG improves performance across model sizes, suggesting it could boost even frontier models
The path toward generally capable embodied agents requires bridging not just vision and language, but also perception and memory, reasoning and experience. Our Graph-RAG framework represents one step on that path—proving that giving AI agents a structured memory can fundamentally change how they plan, act, and learn in complex environments.
Project Resources
The complete implementation, including the Graph-RAG framework, Neo4j integration, and evaluation scripts, is available on GitHub:
Repository: github.com/0xlel0uch/EmbodiedMinds
This repository contains code for both the Visual ICL and Graph-RAG projects, with detailed setup instructions, Neo4j configuration, and examples of querying the knowledge graph for agent decision-making.
This research was completed as part of the Multimodal Machine Learning course (11-777) at Carnegie Mellon University in Fall 2024, in collaboration with Abhi Vakil, Daniel Chang, and Michael Zheng. The project demonstrates how classical database techniques can enhance modern neural approaches, creating hybrid systems that are greater than the sum of their parts. Full implementation and reproducible experiments are available in the GitHub repository.
Suggested Posts
Teaching Robots to See and Act: Building a Vision-Language Model for Precise Manipulation
Exploring how combining 3D perception, depth estimation, and visual in-context learning enables embodied agents to achieve 71.67% accuracy on complex manipulation tasks, outperforming state-of-the-art multimodal language models.
Teaching LLMs to Reason About Finance: A Deep Dive into FinQA
Exploring how large language models can understand financial reports through symbolic reasoning, comparing in-context learning with LoRA fine-tuning, and integrating external tools for reliable quantitative analysis.
Building the Future of Autonomous Trading: From User Intent to Agent Execution
Exploring how the Agentic Trading Platform transforms cryptocurrency trading through intelligent agents that operate autonomously with user-defined strategies and risk parameters.